Selected Systems & Deployments
AI systems architected, built, and operated in live production environments.
PA-Agent — Live System
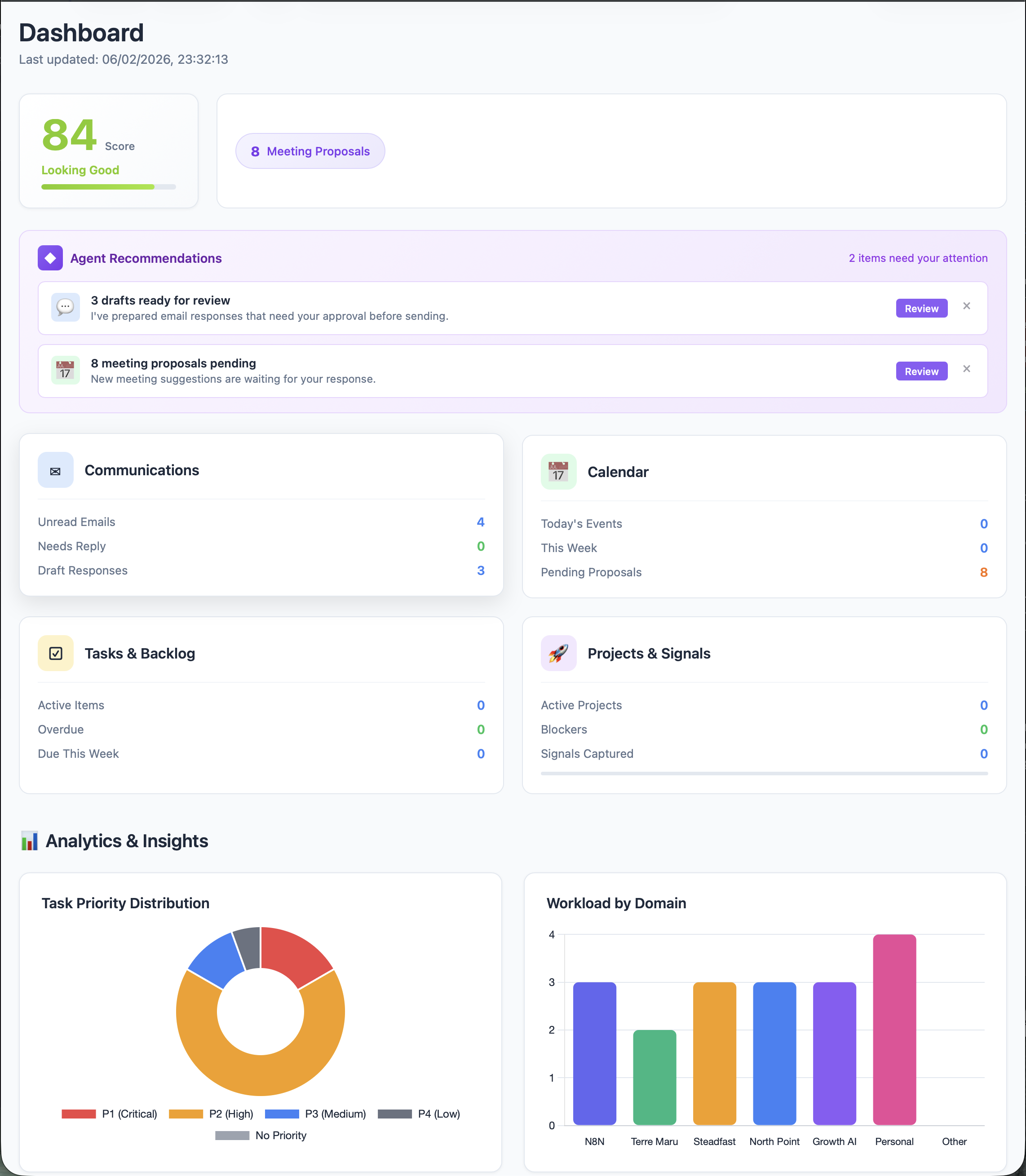
Live dashboard. Real-time priority scoring (84/100), agent-generated recommendations, communications triage, and workload analytics across six client domains. Production deployment.
Production authentication. Username/password with Google Authenticator TOTP. Every session is authenticated and logged.
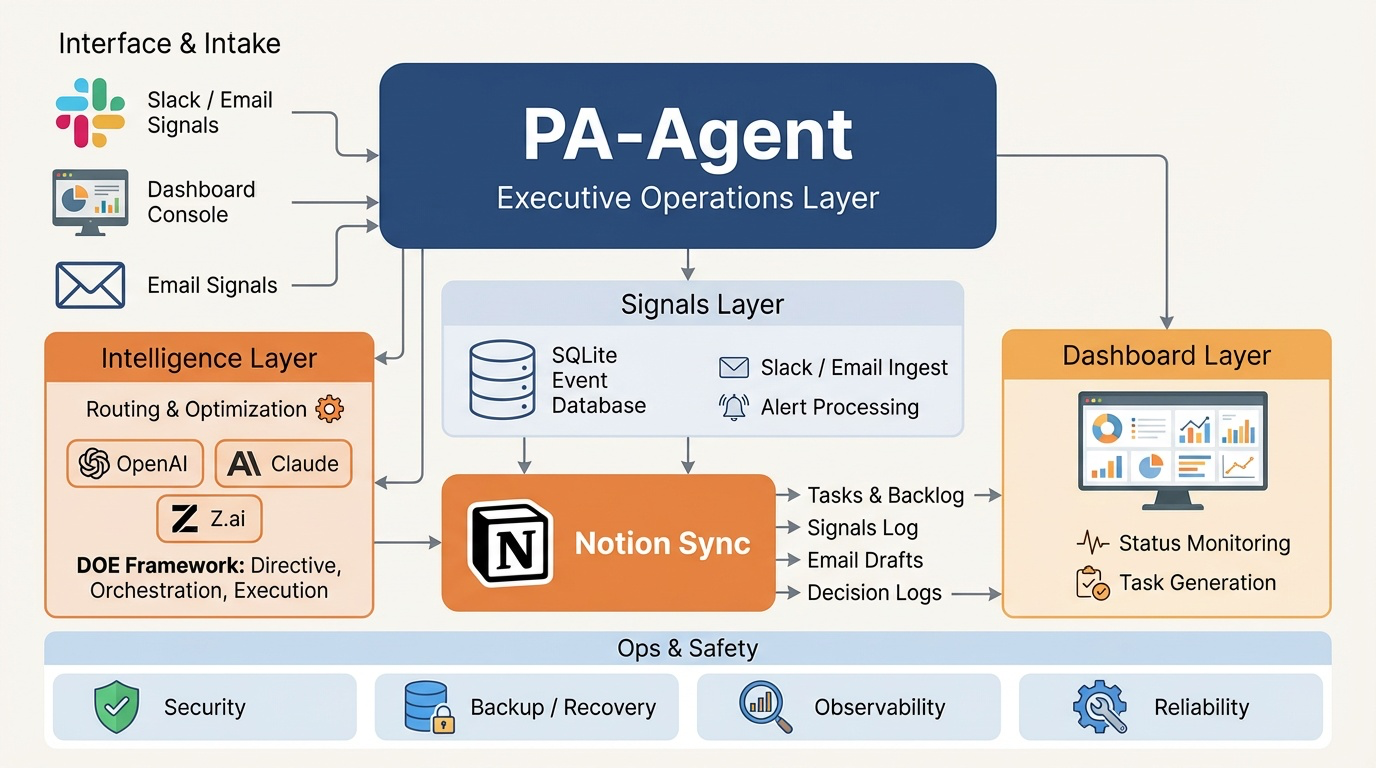
System architecture. Signal intake through orchestration, intelligence routing, persistence, and operational safety controls.
How PA-Agent Works
- Signals → Jobs → Workers → SQLite → Dashboard → Notion. Email, calendar, and Siri signals are ingested into a job queue, routed by a dispatcher to 18 specialised workers, persisted in SQLite, and surfaced through a real-time dashboard with bidirectional Notion sync.
- Deterministic. Auditable. Safe by default. Every decision is logged. No autonomous financial or legal action without explicit human approval. Full audit trail from signal intake through task completion.
- Multi-model routing. LLM calls are routed through OpenRouter (OpenAI, Claude, Gemini) based on task type—triage, summarisation, draft generation, and weekly review each use the model best suited to the job.
- Operator-in-the-loop. The system recommends actions (email drafts, meeting proposals, priority changes). The operator reviews and approves. The system never sends, schedules, or commits on its own.
Content Automation Engine — Live System
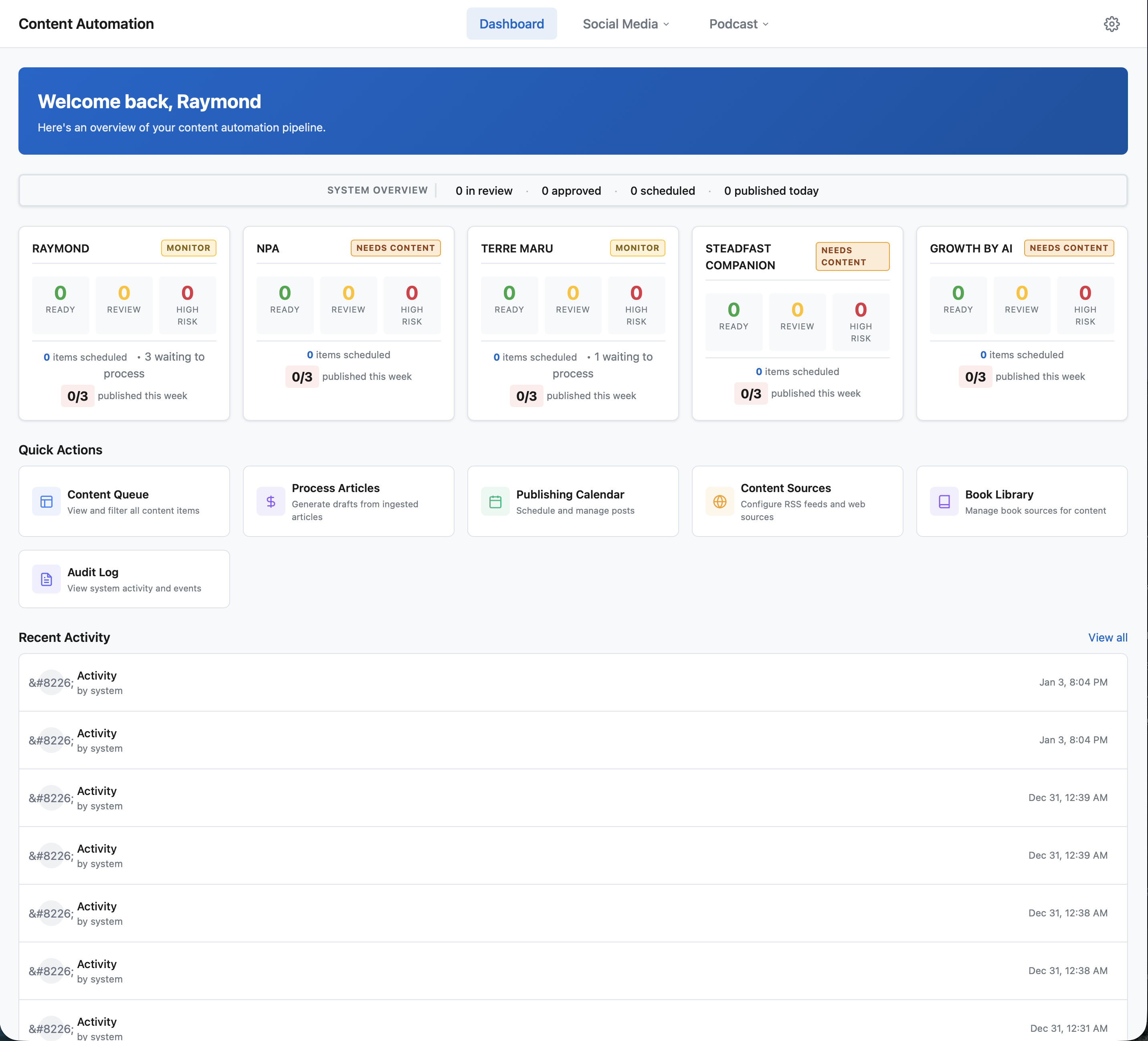
Live pipeline dashboard. Multi-brand content queues across 5 brands, each with independent tone packs, personas, and publishing rules. Items tracked through ingestion, AI draft, governance review, and scheduled publishing. 34,000+ lines of TypeScript. 50+ API endpoints. Production deployment.
Production authentication. JWT-based auth with Admin/Reviewer/Viewer roles and brand-scoped permissions. Every session and mutation logged for compliance.
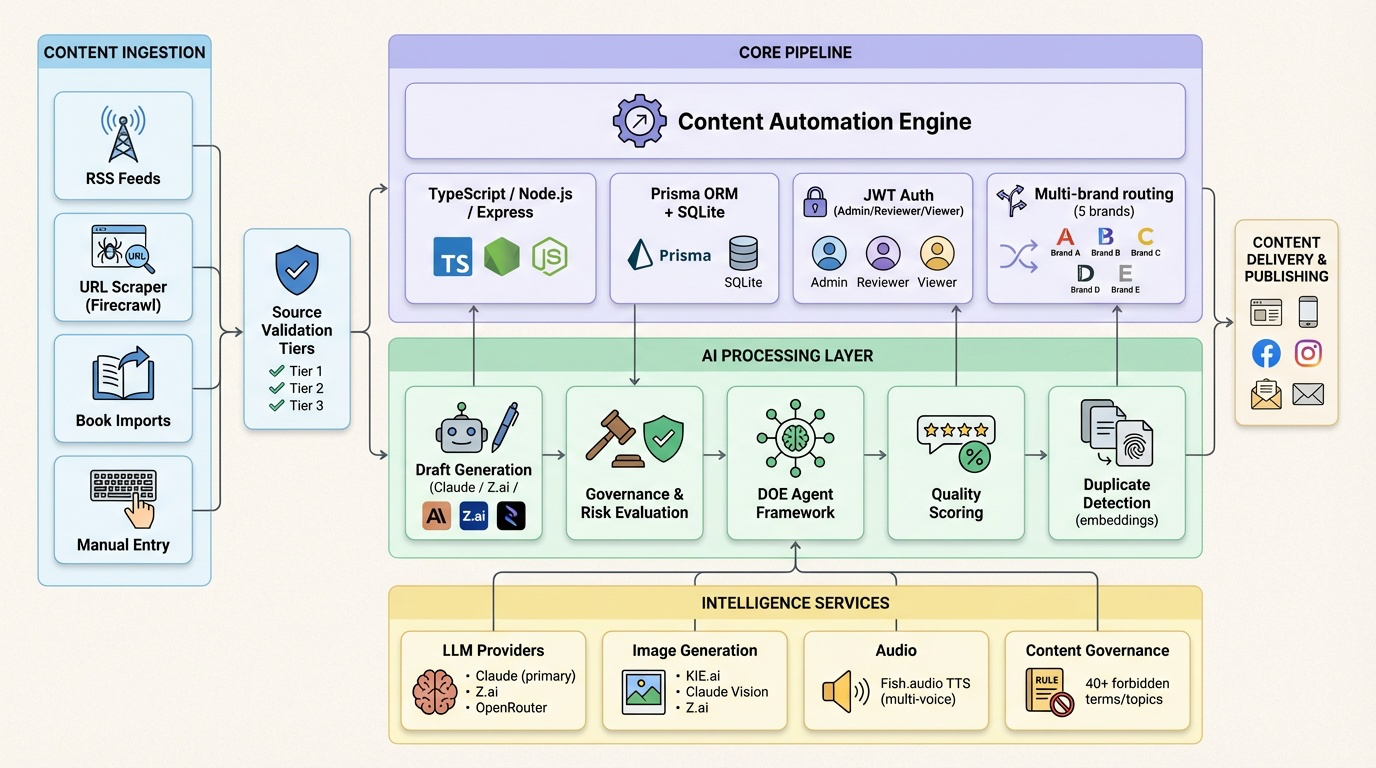
System architecture. Core engine with quality gates and audit logging, knowledge base for brand consistency, intelligence layer with 3 LLM providers (Claude, Z.ai, OpenRouter), and enhancement loop with user feedback.
How the Content Engine Works
- Ingestion → AI Draft → Governance → Human Review → Media Generation → Scheduled Publishing. Source material (RSS feeds, URLs, books, manual input) is transformed into publish-ready content—AI-generated drafts, images, podcast audio, and carousel posts—with risk evaluation, vocabulary compliance, and duplicate detection before anything publishes.
- 3 LLM providers, 7 external integrations. Claude (primary), Z.ai, and OpenRouter with automatic fallback. Image generation via Kie.ai and Claude Vision. Podcast pipeline via Fish.audio TTS with multi-voice stitching. Publishing to 9 platforms via Blotato API.
- Multi-brand engine with governance. 5 brands, each with unique tone packs, personas, guardrails, and publishing rules. Content governance includes risk evaluation, 40+ forbidden term enforcement, duplicate detection via embedding similarity, and source validation tiers.
- Audit-first architecture. 24 Prisma models, 14+ indexed query paths. Every mutation creates an audit entry. Inspector view provides forensic deep-dive into any content item’s full revision history. Role-based access with brand-scoped permissions.
Systems Built
Content Automation Engine
- Problem Content creation across 5 brands required manual drafting, image sourcing, audio production, and platform-by-platform publishing with no governance, no duplicate detection, and no audit trail.
- What was built Full-stack content platform (34,000+ lines TypeScript, 50+ endpoints, 24 Prisma models) automating ingestion through publishing. Multi-brand engine with per-brand tone packs, personas, and guardrails. AI draft generation with 3 LLM providers and automatic fallback. Content governance with risk evaluation, vocabulary compliance (40+ forbidden terms), and duplicate detection via embedding similarity. Image generation, podcast pipeline with multi-voice TTS, carousel support, and scheduled publishing to 9 platforms.
- Impact Reduced content production cycle from 3–5 days to 6–8 hours while maintaining governance compliance and brand consistency.
PA-Agent
- Problem Executive operations spread across email, calendar, Notion, and iCloud with no unified triage, priority scoring, or follow-up tracking.
- What was built Unified operations layer with signal ingestion (Siri, Gmail IMAP, CalDAV), job dispatcher routing 30+ command types to 18 specialised workers, real-time dashboard with priority scoring and workload analytics, bidirectional Notion sync, and 2FA authentication.
- Impact Eliminated 12+ hours of weekly email processing and reduced executive decision latency from days to hours through automated triage and priority scoring.
Book Editor System
- Problem Manuscript preparation required multiple rounds between authors and formatters—inconsistent typography, no DPI validation, manual cover calculations, and no single-source multi-format export.
- What was built 5-stage pipeline (Ingest, Analyse, Review, Scrub, Export) with font-based heading detection, image DPI validation, extensible style-guide rule engine (British/American English), calculated spine-width cover templates, and auditable before/after change logs. Exports production DOCX, print-ready PDF, and EPUB from a single source.
- Impact Reduced manuscript preparation time from 40+ hours to under 2 hours per book with automated style enforcement and multi-format export from a single source.
Persona Wrapper
- Problem Routing user messages to the right AI persona required either expensive LLM calls for every message or brittle if/else chains that broke with new personas.
- What was built Agent router with 5-tier deterministic routing (explicit override, natural language detection, keyword matching, priority tie-break, fallback), three-stage response governance (drift control, hallucination dampening, structure enforcement), and bounded memory with access-tracked prioritisation. Supports multiple LLM backends (Gemini, Claude, DeepSeek) with per-persona model selection.
- Impact Eliminated 80% of routing LLM calls while maintaining 95%+ persona detection accuracy, reducing per-message latency from 2.3s to 0.4s.
- Screenshots are from real, running production systems
- Screenshots may reflect redacted or synthetic data fields
- Some details are intentionally abstracted for security and confidentiality
- No production access granted without written agreement
- Live system walkthroughs and code samples available upon request
- Additional systems and architecture deep-dives available upon request